Sample Page
Privacy and LLMs
Any organisation with company specific intellectual property that spans thousands or hundreds of thousands of documents;. LLMs are great with the source knowledge, what we mean they can answer the questions if they’ve seen the data earlier. They surely weren’t trained on company’s private data, confluence pages, customer specific data, customer inputs.
So, in essence, if you ask a question on your private data, LLM will go blank. LLM improvements would never include such unique, proprietary knowledge and then there is the issue of privacy.

Enterprises and organisations amass data over time — on cloud object stores, in massive data lakes, in internal databases, confluence pages, slack, share point and so on. Wouldn’t it be good to get a curated answer prepared from the company’s proprietary data.
While many organisations are inclined towards cloud-based RAG solutions, there’s a growing sentiment towards local RAG implementations. This shift is driven primarily by concerns over data privacy. Opting for a local RAG system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information.

No organisation wants to take shortcuts in achieving the AI maturity.
How about using Open source LLMs?
An alternate scenario to protect private knowledge is to leverage an open source LLM's. Open source LLMs become more and more capable and LLM training/fine-tuning becomes more user friendly, those companies that are currently using RAG, may pivot to actually training/fine-tuning an LLM for their specific needs. In this way, with locally run models, intellectual property becomes part of the knowledge of the trained LLM and privacy can also be maintained. This approach comes with another challenge, challenge of updating LLM with real-world knowledge over time.
Pivot to ‘business’ needs
Organisations are set to harness the power of LLMs on proprietary data. The focus of organisations is primarily to get storage and infuse aspects needed by them to harness the power of LLMs on proprietary data.
The ideal AI architecture consume all internal data, apply models of one or multiple GPT services and let users experience the outcomes in real time.
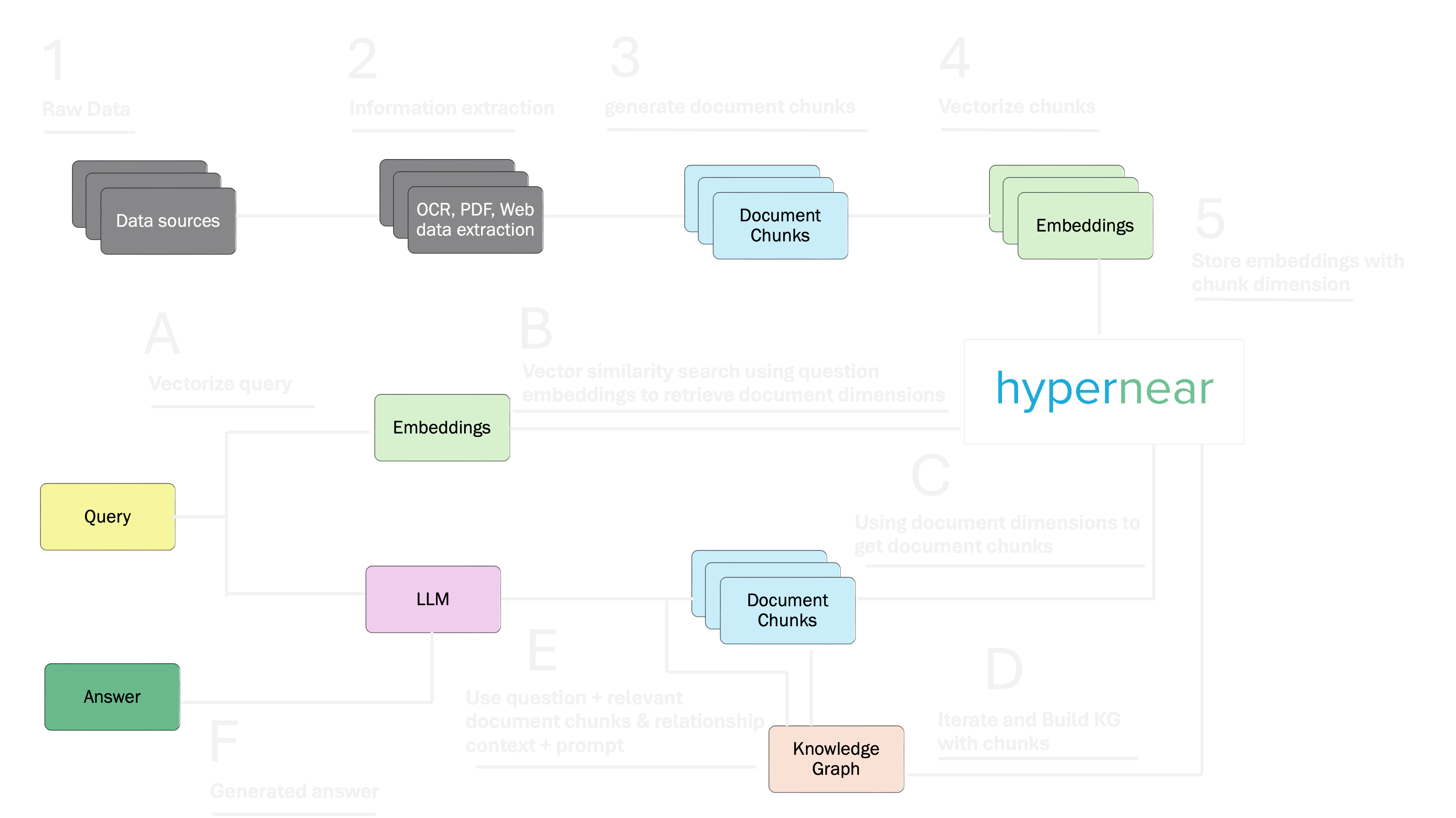
How does it works with local hypernear installation
Hydrate hypernear
Using standard ingestion techniques or APIs ingest data into hypernear. Hypernear will store the data vectors and corresponding metadata
Perform 2-hit search on private data
Hit LLM to get vector for query prompt. Perform vector search of the user input with the hypernear to find matches, enrich the context of the payload, send this reduced payload to the LLM in the second hit.
Leverage LLM
With the context formed, we now want the LLM to perform the recommendations. The matches are sent to the LLM APIs. LLM completes users’ requests and sends the response back.