

Unlock high performance of Transfer Learning with transformer based Neuron architecture on Inferentia Neurons
We can accelerate our existing framework application with minimal code changes whether they are native PyTorch models or native Tensorflow models on Neurons.

Organising for Generative AI: why CEO needs to know this?
Generative AI is a subset of Deep learning, it uses artificial neural network, can process both labelled and unlabelled data using supervised, unsupervised and semi supervised methods. Generative Deep learning model, learn patterns in unstructured content, generate new data that is similar to data it was trained on.

A human’s guide to Foundation Models & unlimited opportunities ahead
Boom of Generative AI Generative AI has taken a boom in recent times. With the advent of Foundation models such

Quick guide to Transformer Architectures
Quick Refresher Rest assured, we’re not revisiting the Transformer model architecture and paper for the 100th time. However, this model

Achieving linear-time operations with shift in attention mechanisms in AI architectures – Mamba, Recurrent Windowed Key-Value
Rapid advancements in AI The field of Large Language Models (LLMs) is currently experiencing rapid development, with a significant focus
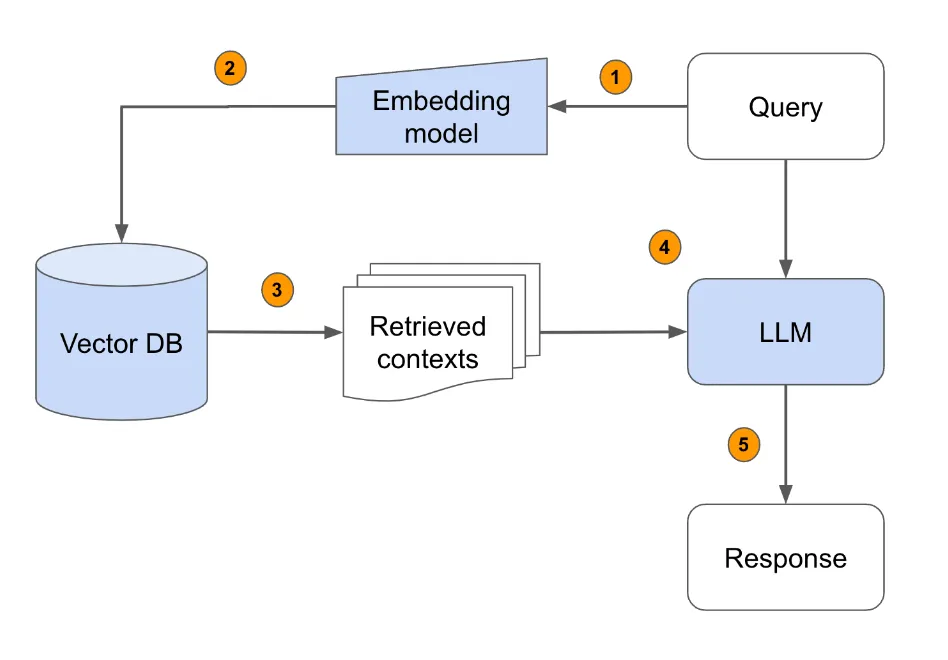
What Retrieval Augmentation Generation (RAG) offers to LLM?
Retrieval-augmented generation (RAG) for large language models (LLMs) aims to improve prediction quality by using an external datastore at inference time to augment a richer prompt that includes some combination of context, history, and recent and relevant knowledge.